


Für Schweiz Tourismus hat Unic ein zweites Rechenzentrum aufgezogen. Dies, um die Plattform MySwitzerland.com auf Basis von Sitecore 9 georedundant betreiben zu können. Massimo Giudice, Senior System Engineer bei Unic, hat den Aufbau des zweiten Rechenzentrums entscheidend mitgeprägt. Im Interview erzählt er, was – oder ob etwas – im Fall einer Katastrophe mit MySwitzerland.com geschieht. Er geht zudem auf die Abhängigkeiten ein, die beachtet werden müssen, wenn eine Sitecore-Architektur auf zwei Rechenzentren aufgesplittet wird.
Beide Rechenzentren sind immer funktionsbereit
Massimo, als System Engineer hast du den Aufbau des zweiten Rechenzentrums geprägt. Wie sieht das dahinterliegende Konzept bezüglich Ausfallsicherheit aus?
Massimo Giudice: Das Sicherheitskonzept für die Plattform MySwitzerland.com sieht synchrone Datenbestände in den zwei Rechenzentren und damit ein Aktiv-Aktiv-Setup vor. Aktiv-Aktiv bedeutet, dass beide Rechenzentren immer funktionsbereit sind. Im Gegenteil dazu übernimmt in einem Aktiv-Passiv-Setup das zweite Back-up-Rechenzentrum nur dann, wenn das Hauptrechenzentrum ausfällt. Mit einem Aktiv-Aktiv-Setup kann das Risiko minimiert werden, dass sich im Fall einer Katastrophe die Website im Backup-up-Rechenzentrum nicht starten liesse.
Um eine maximale Ausfallsicherheit garantieren zu können, haben wir sämtliche Konfigurationsdomänen zwischen den zwei Rechenzentren getrennt. So verfügt das zweite Rechenzentrum zum Beispiel über einen eigenen Internetanschluss eines anderen Anbieters, dessen Router und Peerings nicht mit dem Hauptrechenzentrum in Verbindung stehen. Wir haben getrennte Firewall- und Load-Balancer-Cluster und auch das Netzwerk ist auf der Ebene von Layer 3 vom Hauptrechenzentrum getrennt. Das bedeutet, dass das zweite Rechenzentrum nicht von etwaigen Network Loops des Ersten tangiert wird. Werden zum Beispiel Änderungen am Load Balancer oder an der Firewall vorgenommen, so betrifft dies immer nur ein Rechenzentrum.
Wie wird denn die Lastverteilung zwischen den zwei Rechenzentren sichergestellt?
Für die Lastverteilung zwischen den beiden Rechenzentren setzen wir auf die Services der Content Delivery Networks (CDNs) von Fastly und Quantil. Fastly ist ein schneller und weltweit gut vertretener CDN-Anbieter. Er verfügt allerdings über keine CDN-Endpunkte hinter der «Great Chinese Firewall». Für Zugriffe aus China wird die Website über das CDN von Quantil ausgeliefert. Die Lastenverteilung der CDNs erfolgt via Cedexis.

Abhängigkeiten von Delivery-, Autoren- und Such-Servern
Welche Abhängigkeiten müssen beachtet werden, wenn man eine Sitecore-Architektur auf zwei Rechenzentren aufsplittet?
Es müssen insbesondere Abhängigkeiten in Bezug auf die Delivery-Server, Autoren-Server und Such-Sever (Solr) beachtet werden.
Der Delivery-Server stellt die Website zur Verfügung. Für einen Teil der Website gibt es Anforderungen an die Persistierung von Sessions. Hierbei musste bestimmt werden, ob die Session-Persistierung auf dem äussersten Load Balancer oder in der Datenbank geschehen soll. Wir haben uns dazu entschieden, die Sessions in der Datenbank zu speichern, da im CDN-Loadbalancing von Cedexis keine Session-Persistierung möglich ist. Werden Sessions nicht persistiert, kann das Ausfüllen von Formularen Probleme verursachen oder gar fehlschlagen. Zum Beispiel dann, wenn bei einer Newsletter-Anmeldung das Formular vom Delivery-Server 1 dargestellt wird, die ausgefüllten Daten jedoch an den Delivery-Server 2 gesendet werden.
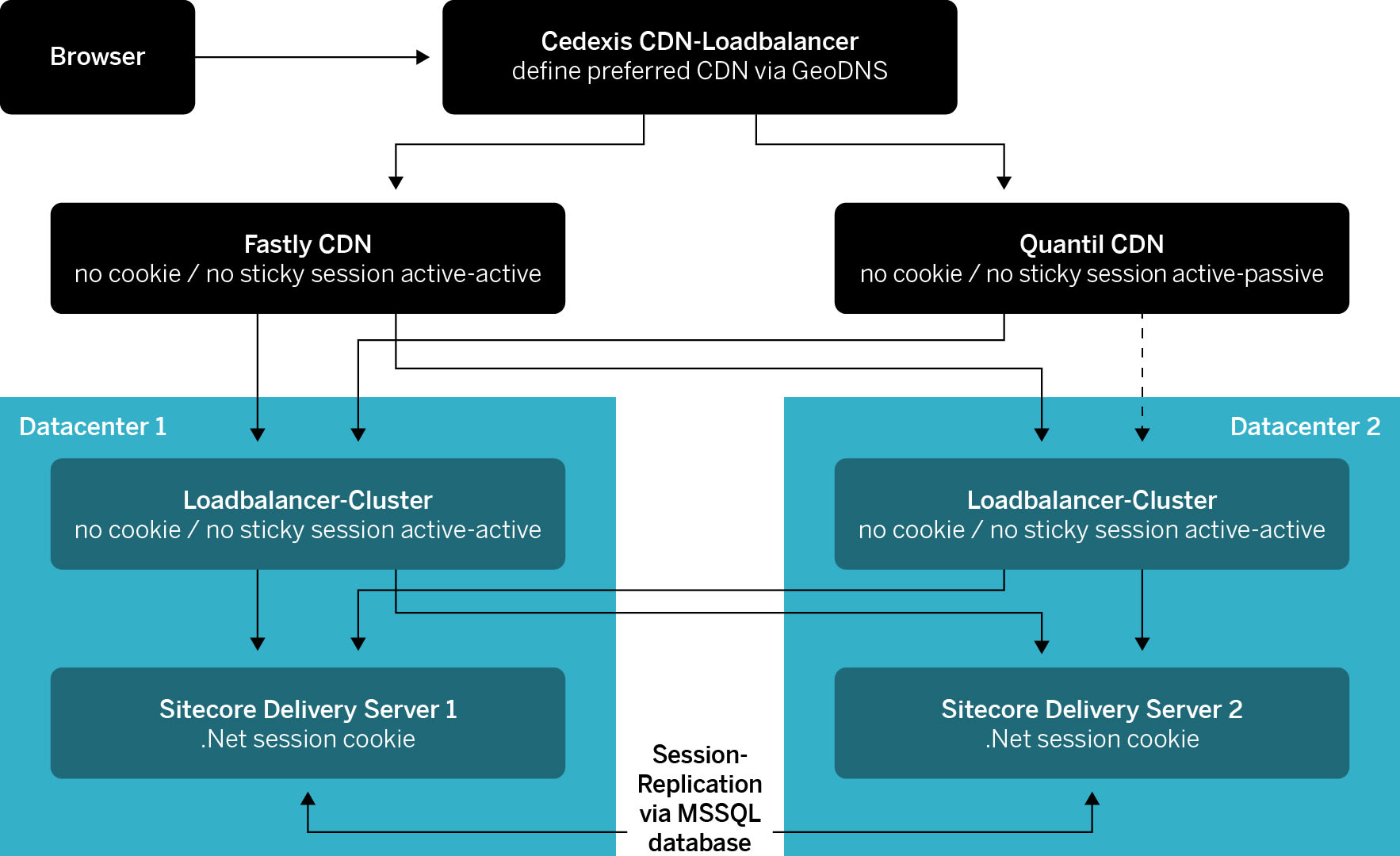
Auf dem Autoren-Server wiederum wird der Content erfasst. Bis zum Upgrade auf den neusten Sitecore Release in ein paar Wochen können wir für den Autoren-Server kein Aktiv-Aktiv-Setup umsetzen. Das heisst, im Fall eines Ausfalls müssen wir die Autoren-Instanz am zweiten Standort manuell hochfahren.
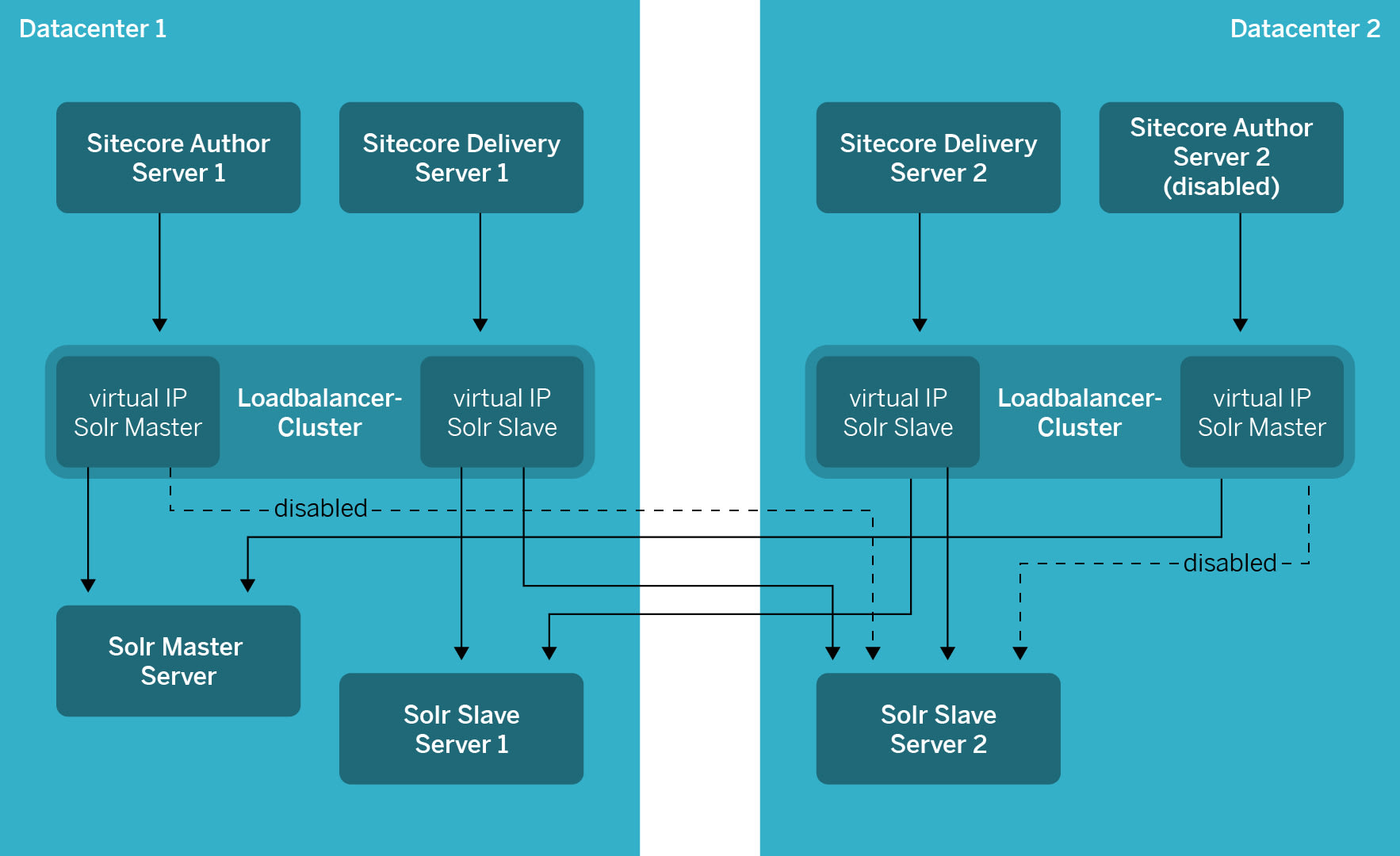
Für den Such-Server (Solr) haben wir uns für ein Master-Slave-Setup entschieden. Bei diesem Setup kann man auf dem Master-Server sowohl lesen und schreiben, auf den Slave-Servern jedoch nur lesen. In unserem Hauptrechenzentrum haben wir den Master- und einen Slave-Server im Betrieb. Im zweiten Rechenzentrum nur einen Slave-Server. Das heisst, wenn das Hauptrechenzentrum ausfällt, ist der Delivery-Server und somit die Webseite weiterhin verfügbar. Der Autoren-Server, welcher nach Solr schreibt, würde entsprechend ausfallen. Bei einem längeren Ausfall ist vorgesehen, dass wir den verbleibenden Slave-Server im zweiten Rechenzentrum manuell zum Master «ernennen». Damit beim Ausfall eines Slave-Server kein Delivery-Server ausfällt, erfolgt der Zugriff via Loadbalancer.
Geringe Latenz dank Routing
Und wie sieht es bezüglich der Latenz zwischen den beiden Rechenzentren aus?
Wenn Server auf mehrere Standorte verteilt werden, muss darauf geachtet werden, dass die Latenz zwischen den beiden Rechenzentren nicht zu gross wird. Denn bei hohen Latenzen kann die Daten-Synchronisation zu Fehlern führen. Um die Fehlerdomänen im Netzwerk einzugrenzen, haben wir uns dazu entschieden, die Netzwerk-Segmente nicht über die zwei Rechenzentren zu erstrecken, sondern zwischen den zwei Rechenzentren zu routen. Um eine tiefe Latenz zu erreichen, erfolgt das Routing über virtuelle Router auf den beiden Switch-Fabrics und nicht über die Firewall-Cluster.
Grundsätzlich sind geclusterte Setups wie das für Schweiz Tourismus immer sehr komplex. Deshalb erachten wir es als äusserst wertvoll, ein Application-Monitoring-Tool (APM) wie Dynatrace im Einsatz zu haben. Das APM hat uns viele Möglichkeiten zur Verbesserung aufgezeigt.
Wann macht ein georeduntantes Hosting Sinn?
Für welche Use Cases macht es Sinn, eine IT-Infrastruktur in zwei räumlich voneinander getrennten Rechenzentren, also georedundant, aufzubauen?
Es macht dann Sinn, wenn das Risiko oder der finanzielle Verlust bzw. Schaden durch den längeren Ausfall einer Website oder Applikation ein Ausmass erreicht, das nicht mehr tragbar ist. Diese Kosten-Risiko-Schätzung muss jedes Unternehmen für sich selber quantifizieren.
Wenn ein Gebäude beispielsweise niederbrennt oder geflutet wird und die Hardware dadurch zerstört wird, kann man mit einem Ausfall von ein bis zwei Wochen rechnen. Zwar ist die Wahrscheinlichkeit, dass eine solche Katastrophe eintritt, sehr gering. Komplett ausschliessen kann man es jedoch nicht.
Bei Schweiz Tourismus ist die weltweite Performance ein wichtiges Thema. Erreicht ihr diese mit den beiden Rechenzentren?
Um in der Schweiz, aber auch weltweit eine gute Verteilung hinzubekommen, haben wir das Autonomous System (AS) in unserem Hauptrechenzentrum mit zwei unterschiedlichen Uplink-Providern verbunden. Einer verfügt über gute Peerings in der Schweiz, der Andere über gute internationale Peerings. Dies sorgt für eine weltweit gute Erreichbarkeit der Rechenzentren.
Wie habt ihr den Failover getestet? Einfach mal den Stecker gezogen?
Wir haben rund 20 bis 30 Szenarien definiert und getestet. Angefangen haben wir beim Testen eines Internet-Uplinks, der entweder im einen oder anderen Rechenzentrum nicht mehr funktioniert. Um diese Situation zu simulieren, haben wir auf Firewall-Ebene den Zugriff blockiert. Des Weiteren haben wir auch die virtuelle Firewall von Schweiz Tourismus runtergefahren. Wir haben ebenfalls getestet, was passiert, wenn die Links zwischen den beiden Rechenzentren ausfallen. Dafür haben wir temporär beide Netzwerk-Ports deaktiviert.
Auch auf Datenbankebene haben wir Failover-Tests durchgeführt. Zu diesem Zweck haben wir die Datenbank-Server offline genommen. Während der Failover-Tests haben wir in der virtuellen Maschine sprichwörtlich das Netzwerkkabel «gezogen». Zudem haben wir gewisse Komponenten in beiden Rechenzentren abgestellt.
Vor Durchführung der Tests haben wir stets festgehalten, mit welchen Impacts wir rechnen müssen, und welche Fehlermeldungen daraus resultieren. Nach der praktischen Verifizierung gab es dann gewisse Dinge, die optimiert werden mussten.
Während der Failover-Tests haben wir in der virtuellen Maschine sprichwörtlich das Netzwerkkabel 'gezogen'.
Massimo Giudice
Senior System Engineer, Unic AG
Im Ernstfall ist die Website weiterhin aufrufbar
Nehmen wir an, es trifft nun wirklich der Ernstfall ein: Das Hauptrechenzentrum fällt aufgrund einer Naturkatastrophe oder eines Anschlags aus. Was passiert?
Im Fall einer Katastrophe liefe die Website MySwitzerland.com ohne Probleme weiter. Änderungen an der Website wären allerdings erst möglich, wenn der Solr-Master wieder in Betrieb wäre. Dazu muss der Slave- zum Master-Server ernannt werden. Danach könnte der Autoren-Server, der eben nicht im Aktiv-Aktiv-Setup betrieben werden kann, im zweiten Rechenzentrum gestartet werden. Um diesen zu starten, haben wir ein klar definiertes Manual erarbeitet. Dieses Manual ist in einem Wiki im Hauptrechenzentrum dokumentiert. Dieses wird unseren Operations-Mitarbeitenden zusammen mit anderen Manuals monatlich als PDF-Export per E-Mail zugestellt.
Inwiefern profitieren auch andere Managed-Services-Kunden von Unic vom zweiten Standort?
Dadurch, dass wir nun ein zweites Rechenzentrum mit den gleichen, konfigurationstechnisch jedoch getrennten Produkten haben, können wir diverse Upgrades zuerst im zweiten Rechenzentrum durchführen: vom Firewall- oder Load-Balancer-Upgrade über die Switched-Fabric- zu den Storage-Upgrades. Wenn bei solchen «Pre-Tests» Probleme auftreten, dann haben diese bloss Auswirkungen auf das zweite Rechenzentrum. So gesehen fungiert das zweite Rechenzentrum für unsere Managed-Services-Kunden als zusätzliche Quality-Assurance-Umgebung.
Darüber hinaus haben wir sehr viel Know-how in den Service-Aufbau des zweiten Rechenzentrums investiert, weshalb wir relativ rasch weitere Kunden im zweiten Rechenzentrum in Betrieb nehmen könnten.



Wir sind da für Sie!
Termin buchenSie möchten Ihr nächstes Projekt mit uns besprechen? Gerne tauschen wir uns mit Ihnen aus.




Kontakt für Ihre digitale Lösung mit Unic
Termin buchenSie möchten Ihre digitalen Aufgaben mit uns besprechen? Gerne tauschen wir uns mit Ihnen aus.

