
Prepared for Disaster: Geo-redundant Hosting for Switzerland Tourism


Carmen Candinas
Unic set up a second data centre for Switzerland Tourism to enable geo-redundant operation of MySwitzerland.com based on Sitecore 9. Massimo Giudice, Senior System Engineer at Unic, played a key role in setting up the second data centre. In this interview, he explains what will happen – if anything – to MySwitzerland.com in case of a disaster. He also expounds on the dependencies to consider when you split a Sitecore architecture between two data centres.
Both data centres are always ready for use
Massimo, as a System Engineer, you played a key role in setting up the second data centre. What is in the concept in terms of fail-safe operation?
Massimo Giudice: The safety concept for MySwitzerland.com is based on synchronous data sets in the two data centres, known as an active/active setup. Active/active means that both data centres are always ready for use. With an active/passive setup, the back-up data centre would only kick in if the main data centre were to fail. An active/active setup reduces the risk of the website in the back-up data centre not starting up in case of a disaster.
To ensure maximum failure resistance, we separated all configuration domains between the two data centres. For instance, the second data centre has its own internet connection with a different provider, whose routers and peering relationships are not connected to the main data centre. We have implemented separate firewall and load balancer clusters and the network is also separated from the main data centre on network layer 3. This means that the second data centre would not be affected by any network loops in the first. E.g. any changes made to the load balancer or the firewall only ever affect one data centre.
And how do you ensure load balancing between the two data centres?
To distribute load between the two data centres, we use the services of Content Delivery Networks (CDNs) by Fastly and Quantil. Fastly is a very fast CDN provider with an excellent global reach. However, they do not have any CDN end points behind the “Great Chinese Firewall”. For requests from China, the website is delivered by the Quantil CDN. Load balancing between the CDNs is provided via Cedexis.

Dependencies regarding delivery servers, author servers and search servers
What dependencies do you need to keep in mind when splitting a Sitecore architecture across two data centres?
In particular, you need to look into the dependencies regarding delivery servers, author servers and search servers (Solr).
The delivery server delivers the website. For part of the website, there are requirements regarding the persistence of sessions. We had to determine whether the persistence of sessions was to be ensured on the outermost load balancer or in the database. We decided to save the sessions to the database, since the CDN load balancing via Cedexis does not allow for session persistence. Non-persistent sessions can lead to issues or failures when people are filling out forms. For instance, when someone signs up for a newsletter and the form is provided by delivery server 1 but the data entered is sent to delivery server 2.
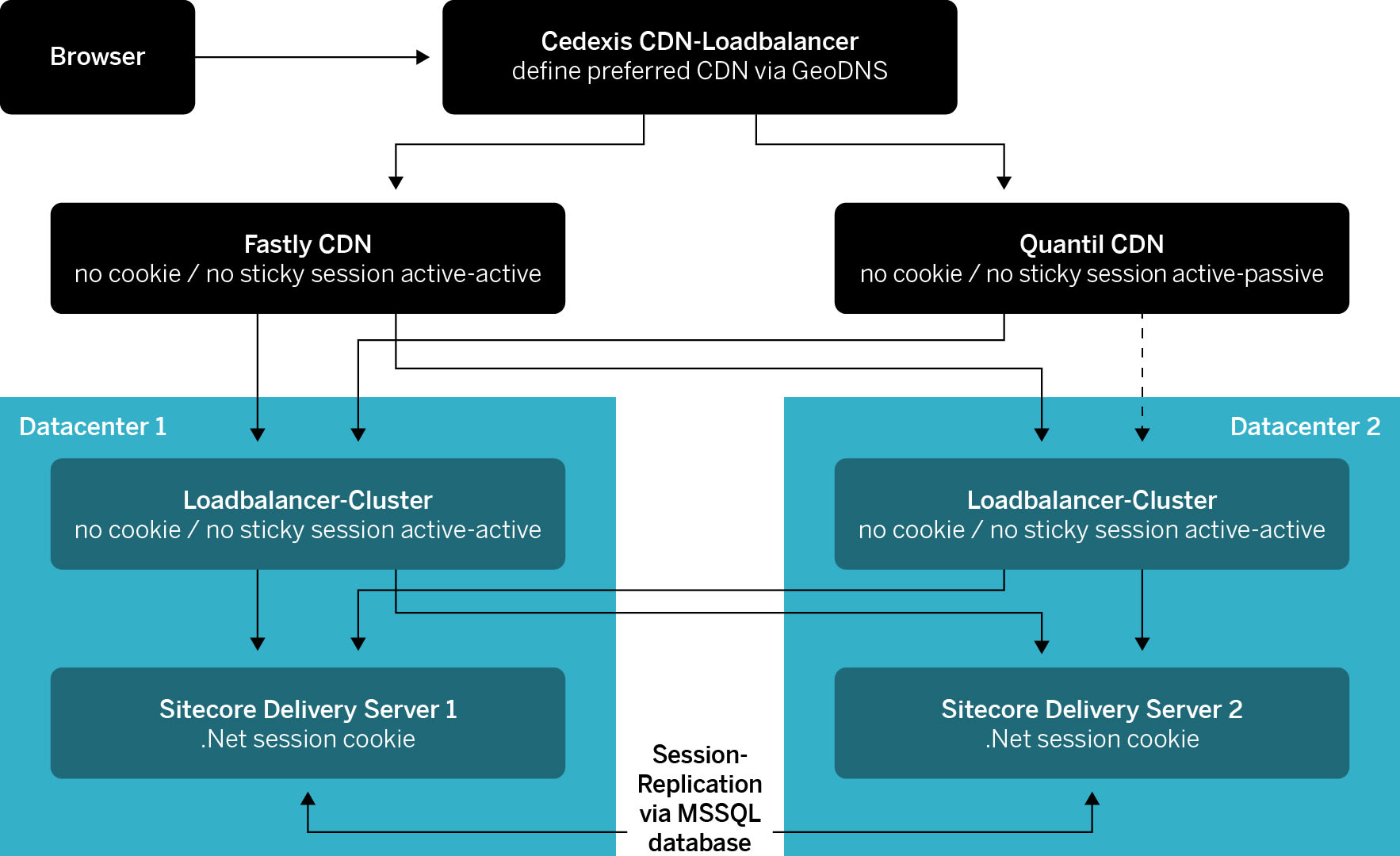
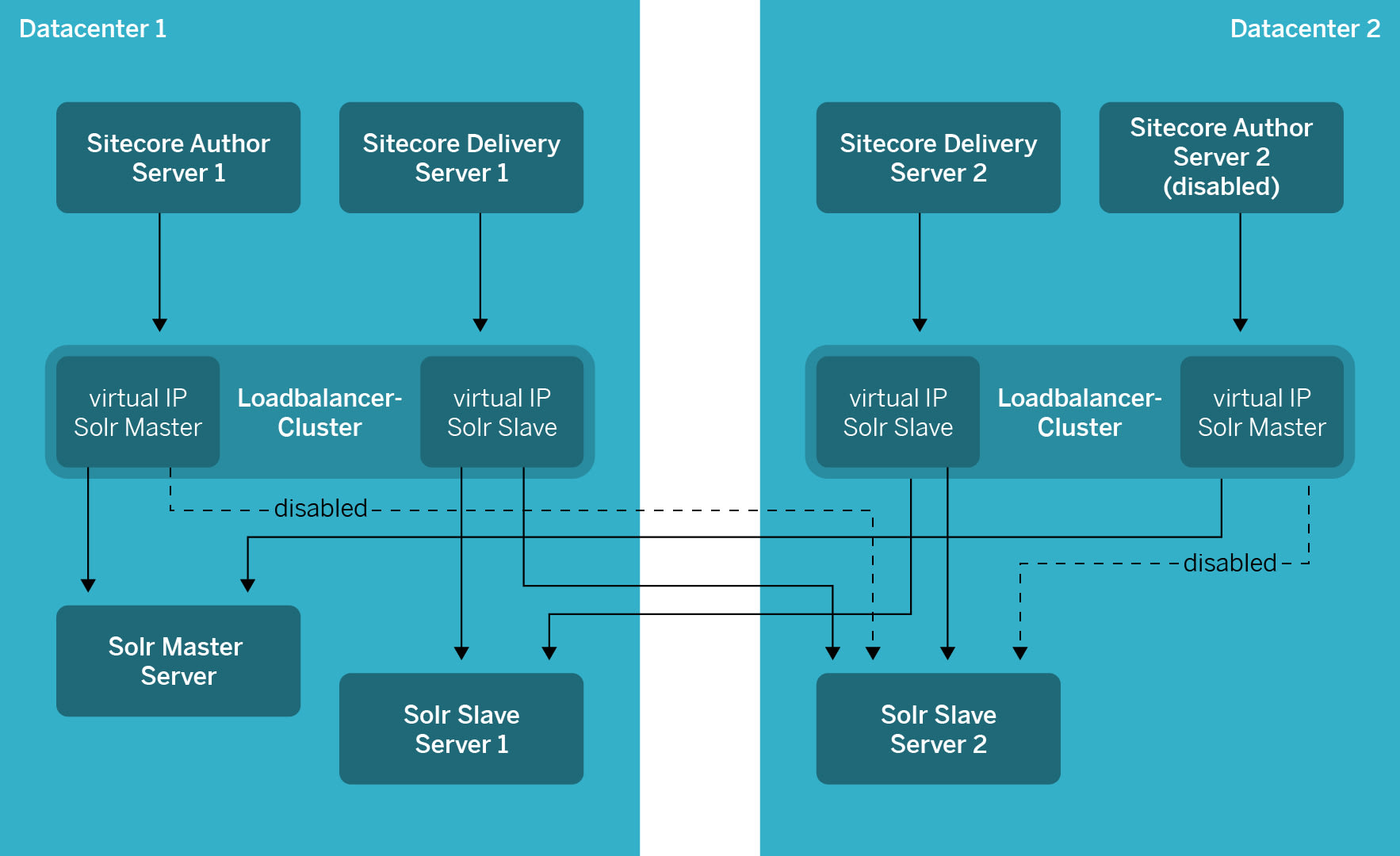
The author server in turn is dedicated to content generation. We will not be able to set up the author server as active/active until the upgrade to the next Sitecore release a few weeks from now. In case of a failure, we will have to start up the author-instance manually in the second location.
For the search server (Solr), we chose a master/slave setup. With this setup, you can read and write on the master server whereas the slave servers are read-only. In our main data centre, we are operating a master and a slave server. In the second data centre, we only have a slave server. Should the main data centre fail, the delivery server and the website would still be available. The author server writing to Solr would fail. In the case of longer downtimes, we would manually redefine the remaining slave server in the second data centre as the master. To make sure no delivery server fails after a failure of a slave server, the requests are managed via a load balancer.
Low latency thanks to routing
And what about the latency between the two data centres?
If servers are placed in different locations, you need to ensure that the latency between the two data centres is not too high. Otherwise, the data synchronisation may generate errors. To narrow down the sources of errors in the network, we decided to not extend the network segments across both data centres, but to route between the two data centres. To keep the latency low, the routing is carried out via virtual routers in the two switching fabrics and not via the firewall clusters.
Generally speaking, clustered setups like the one for Switzerland Tourism are always very complex. That is why we find it tremendously helpful to run an application monitoring tool (APM) such as Dynatrace. The APM has shown us many ways to improve the setup.
When does geo-reduntant hosting make sense?
For which use cases does it make sense to set up a geo-redundant IT infrastructure in two physically separate data centres?
It makes sense to do this if the risk or the financial losses or damage in the case of longer downtime of a website or application reach a magnitude that is no longer tolerable. This cost and risk assessment is something that every company will have to do individually.
If, for example, a building was to burn down or be flooded and the hardware was to be destroyed, this would lead to a downtime of one or two weeks. The likelihood of such a disaster striking is admittedly very small. However, it can never be fully excluded.
Switzerland Tourism needs to perform well globally. Is that something you can ensure with the two data centres?
To achieve good distribution within Switzerland but also globally, we connected the autonomous system in our main data centre to two different uplink providers. One has good peering relationships within Switzerland, the other one has good international peering. This gives us decent global availability of the data centres.
How did you test the failover? Did you just pull the plug?
We defined and tested between 20 and 30 different scenarios. We started testing with a malfunctioning internet uplink in one of the two data centres. To simulate this situation, we blocked access on the firewall level. We also shut down the virtual firewall for Switzerland Tourism. In addition, we tested what would happen if the links between the two data centres were to fail. For that, we shut off both ports temporarily.
We also performed failover tests on the database level. For this purpose, we took the database servers offline. During the failover tests, we literally pulled the plug on the virtual machine. We also switched off certain components in both data centres.
Before we carried out the tests, we always listed the impact we expected to see and the error messages this would generate. After the practical test and verification, certain things needed to be optimised.
During the failover tests, we literally pulled the plug on the virtual machine.
Massimo Giudice
Senior System Engineer, Unic AG
In case of a disaster, the website would be accessible
Let’s say disaster strikes: The main data centre fails due to a natural disaster or an attack. What happens next?
In case of a disaster, MySwitzerland.com would just keep running without any problems. However, changes to the website would only be possible once the Solr master was recovered. To achieve this, the slave server would have to be redefined as the master. After that, we could boot the author server, which cannot be operated in an active/active setup, in the second data centre. We have written a clear and concise manual on how to do that. This manual is available from a wiki in the main data centre. We also send it out to our operations employees as a PDF export via email once a month, together with other manuals.
Do Unic’s other managed services customers also profit from the second location?
Since we now have a second data centre with the same set of products which can be configured separately, we can perform various upgrades in the second data centre first, be it firewall upgrades, load balancer upgrades, switching fabric upgrades or storage upgrades. Should any issues arise during these “pre-tests”, they would only affect the second data centre. This makes the second data centre an additional quality assurance environment for our managed services customers.
We also invested a lot of expertise in the service setup of the second data centre, which means we are now able to set up other customers in the second data centre fairly quickly.


Contact for your Digital Solution
Book an appointmentAre you keen to talk about your next project? We will be happy exchange ideas with you.




Contact for your Digital Solution with Unic
Book an appointmentAre you keen too discuss your digital tasks with us? We would be happy to exchange ideas with you.

